The basic equation that describes the update rule of gradient descent is. This update is performed during every iteration. Here, w is the weights vector, which lies in the x-y plane. From this vector, we subtract the gradient of the loss function with respect to the weights multiplied by alpha, the learning rate.
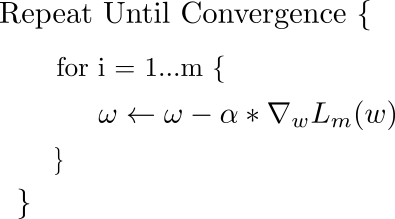
https://towardsdatascience.com/understanding-backpropagation-algorithm-7bb3aa2f95fd#:~:text=The%20algorithm%20is%20used%20to,parameters%20(weights%20and%20biases).
No comments:
Post a Comment